[ASICs] [Chip Typen] [Chip Aufbau] [Entwicklung] [Schnittstellen] [Glossar]
[Chip-Gehäuse] [IO-Bereich] [Spannungsversorgung] [Core Area] [Taksignale] [Makros] [Verdrahtung] [Wafer]
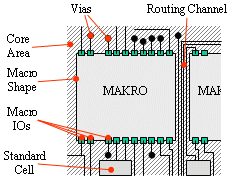 Verdrahtung der Metalllagen (Routing)
Verdrahtung der Metalllagen (Routing)
In den vorausgegangenen Seiten sind verschiedene aktive Elemente sowie die Spannungsversorgung eines Chips vorgestellt worden. Die sequentielle und kombinatorische Logik einer Schaltung - sei es als Netzliste oder als Makro - macht jedoch nur einen Teil eines ASICs aus. Den bisher noch nicht angesprochenen passiven Teil einer Schaltung kann mit seinen Einflüssen und Auswirkungen auf die Schaltung - und die ASIC-Entwicklung im Allgemeinen - keinesfalls vernachlässigt werden. Dieser Teil besteht schlicht und einfach in den elektrischen Verbindungen zwischen den Schaltungselementen, die im Layout-Prozeß erzeugt werden. Das Layout besteht im Wesentlichen aus dem Placement (Plazierung) und dem Routing (Verdrahten). Daher spricht man beim Layout auch vom Place & Route oder auch kurz P&R.
Placement
Bevor die Elemente verdrahtet werden können, muß jedem Element in der Schaltung in einem ersten
Schritt auf der zweidimensionalen Chipfläche ein fester Platz zugewiesen werden. Dieser Prozeß wird als Placement bezeichnet. Die Größe und Geometrie der Elemente entnimmt das Plazierungstool aus der
jeweiligen ASIC-Library und ist so in der Lage, generelle Technologieregeln anzuwenden, Überlappungen der Geometrien zu vermeiden und ein Abbild der plazierten Netzliste auf dem Monitor
darzustellen. Für die Aufgabe der Plazierung haben sich im Laufe der Zeit verschiedene Strategien entwickelt, die letztlich die Herausforderungen der immer kleiner werdenden Strukturen neuer
Technologien bei komplexer werdenden Schaltungen widerspiegeln:
- Random Placement
Mit den alten ASIC-Technologien konnten zunächst nur relativ kleine und langsame Schaltungen implementiert werden. Die Verzögerung innerhalb der aktiven Elemente ist deutlich größer als die Verzögerungen in den elektrischen Verbindungen. Die Plazierung kann hier daher noch unabhängig von der Netzlistenstruktur und anderen Layout-Parametern (Timing) durchgeführt werden. Zwar können bestimmte Elemente wie z.B. Root-Buffer eines Clock Trees optimal von Hand vorplaziert werden (IO-Buffer befinden sich natürlich immer in den IO-Slots um die Core Area herum), jedoch wird die überwiegende Mehrzahl der Elemente innerhalb der Core Area mehr oder weniger irgendwohin plaziert. Mit steigender Anzahl von Elementen und kleiner werdenden Technologiestrukturen stößt diese Strategie jedoch an ihre Grenzen, da sich nach dem Routing (s.u.) immer mehr Verbindungen gegenüber den Design-Constraints als zu langsam herausstellen und nachgebessert werden müssen. - Timing Driven Placement
Die Plazierung der Elemente wird anhand der aktuellen Signalverzögerungen ausgerichtet. Dieses Timing wird aus Wireload-Modellen heraus lediglich grob abgeschätzt, da diese Modelle aus statistischen Verteilungen der Signalverzögerungen verschiedener Netzlisten ermittelt worden sind. Diese verbesserte Plazierungsstrategie wurde benötigt, da bei neueren Technologien der Anteil der Gesamtverzögerung eines Signals sich mehr und mehr auf die elektrischen Verbindungen verschoben hat. Ein kurzes Routing und die damit verbundene optimale Plazierung, wurde immer essentieller. - Layout Driven Placement
Auch hier wird die Plazierung der Elemente anhand der aktuellen Signalverzögerungen ausgerichtet. Jedoch wird das Timing nicht aus den groben Wireload-Modellen statistisch abgeschätzt, sondern aus den bereits vorgenommenen aktuellen Plazierungen heraus durch eine Abstandsberechnung für jedes einzelne Signal relativ genau ermittelt. Kann dann ein Timing-Constraint nicht erfüllt werden, wird direkt das Placement der entsprechenden Elemente korrigiert.
Routing
Verbindungen zu planen ist im Layout-Prozesses neben der Plazierung der aktiven Elemente die zweite
entscheidende Aufgabe. Während die elektrischen Verbindungen innerhalb der Basiselemente (z.B. zwischen den einzelnen Transistoren eines UND-Gatters oder die innerhalb eines RAM-Makros) schon
fest vorgegeben sind und im Layout nicht verändert werden können, müssen die elektrischen Verbindungen auf der Ebene der Netzliste entsprechend vorgegebener Zeit- und Flächenvorgaben
gezogen werden. Dieser Vorgang der Planung und Erstellung der Verbindungsleitungen wird Routing genannt.
Während die Transistoren der aktiven Bauelemente in den ersten Schritten im Substrat des Wafers durch
Diffusionsprozesse entstehen, werden die elektrischen Verbindungen nach der Diffusion in so genannten Metalllagen (Metal Layer) auf der Chipoberfläche oberhalb der Transistorstrukturen (Substrat)
aufgedampft. Je nach Technologie und Erfordernissen des ASIC-Designs werden mehrere Metalllagen nacheinander aufgebracht, die untereinander durch je eine Isolationsebene elektrisch isoliert sind. Die
Anzahl der Metalllagen liegt bei neueren Technologien im Bereich von 4 bis 10. Theoretisch sind natürlich mehr möglich.
Verbindungen zwischen den Metalllagen
Gewollte Verbindungen zwischen den einzelnen Metallebenen werden durch so genannte Vias erzeugt. Wie bei einem PCB können durch Vias
- elektrische Leitungen mit den aktiven Elementen (entweder direkt mit den Transistoren oder indirekt über deren lokalen Metallisierungsleitungen) verbunden werden
- Hindernisse auf einer Ebene (z.B. eine querende Signalleitung) über eine oder mehrere andere Metallebenen überwunden werden
- aktive Elemente mit den Metalllagen der Versorgungsspannung verbunden werden
Zusätzlich müssen mit Vias DSM-Aspekte (Deep Sub Micron) berücksichtigt werden, die während der Chipproduktion auftreten. Man spricht in diesem Fall der Berücksichtigung dieser Aspekte von DFM
bzw. von Design for Manufacturing.
Soll über ein Via mehrere Metalllagen überbrückt werden (z.B. Verbindung zwischen der 2. und 5.
Metalllage), dürfen sich im Bereich des Vias in den dazwischen liegenden Lagen (3. und 4. Metalllage) natürlich keine Signal- bzw. Versorgungsstrukturen aus Metall befinden.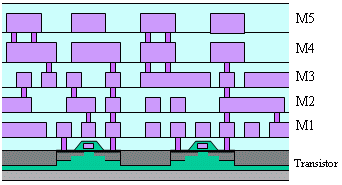
Spezialisierung der Metalllagen
Um die Metalllagen einerseits effektiv zu nutzen und andererseits eine hohe Leistungsfähigkeit (Performance) zu erzielen,
werden den einzelnen Lagen ausgehend vom Substrat bestimmte Aufgaben zugeordnet. Die Abbildung rechts zeigt einen Querschnitt durch einen Chip mit 5 Metalllagen M1 bis M5. Eine im folgenden als "Ebene"
bezeichnete Verbindungsstruktur kann je nach Technologie sowohl aus einer als auch aus einigen wenigen Metalllagen bestehen. Eine funktionale
Vermischung der Aufgaben zwischen diesen Ebenen ist zwar ohne Weiteres möglich, wird jedoch nach Möglichkeit vermieden.
- Lokale Verbindungen auf Transistor- und Primitive-Ebene
Auf dieser untersten Ebene werden aus einzelnen Transistoren des Substrats durch elektrische Verbindungen Gatter, Flipflops und kleinere Makros aufgebaut. Der daraus resultierende kurze Abstand zu dem Substrat und deren Transistoren garantiert eine kleine Elementfläche und kurze Via-Verbindungen mit entsprechend geringen parasitären Kapazitäten und eine daraus resultierende hohe Schaltgeschwindigkeit. - Verbindungen in der Modul Ebene
Größere Elemente, die auf der ersten Ebene nicht komplett verdrahtet werden können, benutzen hierzu die zweite Modul Ebene. Insbesondere komplex und kompakt aufgebaute Makros wie z.B. RAMs nehmen von dieser Ebene Gebrauch. Sind keine "Module" (global oder lokal) definiert/vorhanden, können die Metalllagen dieser Ebene von anderen Ebenen genutzt werden (Clock Tree oder globales Routing) - Verbindungen in der Clock Tree Ebene
An einen Clock Tree werden gegenüber den normalen Signalleitungen spezielle Anforderungen gestellt. Dieses sind eine möglichst kurze Signallaufzeit (gemessen vom Root Buffer des Clock Trees bis zu den einzelnen Flipflops).). Die Laufzeitunterschiede (Clock Skew) zwischen den einzelnen Leaf Cells soll dabei möglichst klein sein. Voraussetzung dafür ist eine möglichst gleichmäßige Struktur des Clock Trees mit möglichst kurzen Signalwegen und wenigen Vias.
Da Taktsignale die höchsten Frequenzen im Design aufweisen und über eine große Chipfläche verteilt werden, müssen diese aufgrund von Übersprechen auf andere Leitungen (DSM, Cross Talk) abgeschirmt werden (Shielding). Shielding besteht im Prinzip aus zu beiden Seiten der Taktleitung geführte zusätzliche Leitungen, die fest auf Ground-Potential geklemmt werden und das elektrische Feld des Clock Trees zum Großteil absorbieren. Details dazu sollen hier nicht weiter aufgeführt werden.
Shielding wird um so nötiger, je kleiner die Strukturen der jeweiligen Technologie sind und je geringer der Abstand zwischen zwei Signalleitungen wird. Um diese Anforderungen möglichst optimal erfüllen zu können, werden die Verbindungen des Clock Trees vorwiegend auf einer eigenen Metallage gelegt (s. auch CTS, Clock Tree Synthesis). DFM-Kompromisse in Bezug auf eine minimale Anzahl von Vias müssen jedoch auch hier aufgrund der DSM-Effekte (Deep Sub Micron) gemacht werden. - Globales Routing
Auf diese Ebenen werden die normalen Schaltungsverbindungen als auch die Signale von Makros gelegt. Da Hard-Makros eigenständige Elemente darstellen, die in ihrem Zeitverhalten komplett spezifiziert sind und von der übergeordneten Schaltung nicht beeinflußt werden dürfen, werden über Hard-Makros i.A. keine Signalverbindungen gelegt, die nicht zu dem Makro selber gehören. Diese könnten sonst das Makro z.B. durch Cross Talk in seinem Zeitverhalten gegenüber der übergeordneten Schaltung verändern und so zu Zeitproblemen führen. - Versorgungsspannungs-Ebenen (VDD und GND)
In den Metalllagen, die für die Versorgungsspannung des Chips reserviert sind, wird ein enges Leitungsnetz, das so genannte Power Mesh, aufgebaut. Das Verhalten der Versorgungsleitungen kann als quasi-statisch angesehen werden. Daher spielen parasitäre Kapazitäten aufgrund langer Vias hinunter zu den aktiven Elementen eine eher untergeordnete Rolle und können daher auf den äußeren Metallebenen realisiert werden. Aufgrund eines hohen Stromverbrauchs oder zur Reduzierung der parasitären Via-Induktivität bei hohen Frequenzen (= häufig wechselnder Stromverbrauch), können u.U. pro Verbindung zwei oder mehr Vias gesetzt werden.
Da gegenüber den Signalleitungen auf den VDD- und GND-Leitungen des Power Mesh ein relativ hoher Strom fließt, fällt hier ein ohmscher Widerstand stärker ins Gewicht. Deshalb werden die Versorgungsleitungen breiter ausgebildet als die Signalverbindungen der Schaltung um einen Spannungsverlust vom Rand des Chips bis zum Kern der Core Area möglichst klein zu halten. Ebenso kann die Dicke der Versorgungsleitungen zur Vergrößerung des Leitungsquerschnitts und zur Reduktion des ohmschen Widerstandes erhöht werden.
Eine Analyse des Stromverhaltens gemessen über die gesamte Chipfläche und damit ein positionsabhängiger Spannungsverlust im Power Mesh kann über eine spezielle Simulation ermittelt werden (IR Drop Analysis oder auch Voltage Drop Analysis). Anhand der Ergebnisse kann festgestellt werden, ob jedes zu versorgende Element unter allen (dynamischen) Betriebsbedingungen ausreichend mit Spannung versorgt werden kann. Voraussetzung dazu ist, daß in der Simulation realistische Einsatzbedingungen nachgebildet werden.
Leitungs-Pitch
Der Pitch, also der minimale Abstand zwischen benachbarten Leitungsstrukturen, kann auf
unterschiedlichen Metallagen verschieden groß sein. Da die Zuführung der Versorgungsspannungen für eine möglichst geringen Zuleitungswiderstand wie eben beschrieben allgemein größere Geometrie
erfordert, sind die Leitungsbreiten und der Pitch bei diesen Metallagen größer als die Leitungsbreiten und der Pitch auf den Signallagen.
Routing Kanäle
Häufig sind auf dem Chip Makros plaziert, über die keine Signalleitungen "von außerhalb" gelegt werden
können. Dieser Tatsache wird häufig bei ASIC-Designs zu einem Routing-Problem, die eine große Anzahl von RAMs enthalten. Um dennoch die benötigte Kapazität von Routing Ressourcen zu haben,
müssen die Makros in einem entsprechenden Abstand voneinander plaziert werden, damit für die zu verdrahtenden Signale zwischen den Makros ein genügend großer Routing-Kanal vorhanden ist (s. Abbildung oben).
Designgröße
Die folgende Beschreibung dreht sich um die Einordnung der "Größe" eines Chips und verschiedene
Parameter, die einen Einfluß auf diese Größe haben. Alle aufgeführten Begriffe spielen sich entweder auf der funktionalen oder der physikalischer Ebene ab. Während die "funktionale Größe" einer Schaltung
durch die Anzahl der Gatter-Äquivalente widergespiegelt wird, bezieht sich die physikalische Ebene auf die Größe der Siliziumfläche des Chips. Manchmal werden beide Ebenen miteinander vermischt und
können nur aus dem Gesamtkontext heraus zugeordnet werden.
Die Größe einer Schaltung, die auf die Core Area eines Chips einer bestimmten Größe untergebracht
werden kann, richtet sich nach verschiedenen technologischen und schaltungsabhängigen Parametern und variiert bei jedem ASIC-Design:
- Technologie
Die Technologie gibt die Rahmenbedingungen des ASICs vor und bestimmt damit auf vielerlei Art und Weise die Größe des Chips. Durch die Technologie wir die Geometrie und der Aufbau einzelner Transistoren und Gatter sowie die Abstände und Größen der elektrischen Verbindungen (Pitch) festgelegt und somit auf Schaltungsebene die physikalische Größe eines NAND-Gates, das als logische Bezugsgröße einer Schaltung für den Gate Count herangezogen wird. - Gate und Gate Count
Unter einem Gate versteht man allgemein die Größe und Funktionalität eines NAND-Gates, das in jeder Technologie vorkommt und eine gewisse Funktionalität widerspiegelt, aus der man andere höhere Funktionalitäten (z.B Complex Gates, Addierer, ...) aufbauen kann. Demzufolge hat ein standard NAND-Gate mit normaler Treiberfähigkeit die Größe "1 Gate" während z.B. Flipflops je nach Typ 5 bis über 10 Gates benötigen und RAMs eine Größe von einigen hundert bis zu vielen tausend von Gate-Äquivalenten haben können. Wie groß der Gate Count eines bestimmten Library Elementes ist, findet man in der Beschreibung der so genannten Block Library, in der alle logischen Elemente der Technologie aufgeführt sind. Der Gate Count einer Schaltung - sei es der eines ASICs oder eines kleineren Makros - ist die Summe der Gatter-Äquivalente aller in der Schaltung vorkommender Elemente. Mit dem Gate Count lassen sich daher die Größen von Schaltungen technologieunabhängig miteinander vergleichen. - Grid
Die Fläche der Core Area eines Chips ist auf unterster Ebene in viele kleine physikalische Flächenelemente aufgeteilt, in denen die Transistoren der logischen Elemente realisiert werden. Die Fläche eines Grids muß nicht quadratisch sein. Daher sind in einer quadratischen Core Area unterschiedlich viele Grids in X- und Y-Richtung angeordnet. Ein Grid ist in einer Technologie immer eine feste Größe und unabhängig von der Chipgröße. Somit befinden sich auf großen Chips mehr Grids als auf kleineren.
Ein Grid ist also die kleinste physikalische Einheit auf dem Chip. Um ein NAND-Gate zu realisieren werden i.A. mehrere Grids benötigt, weshalb ein gewisser Bezug zwischen Grid und Gate hergestellt werden kann, z.B. 1 Gate = 4 Grid. Dieser Bezug ist aufgrund der Unschärfe des Gate Counts nicht exakt und stellt nur eine gewisse Näherung zischen der logischen Schaltungsgröße und der physikalischen Chipgröße dar. Das Verhältnis zwischen Grid Count und Gate Count kann von Technologie zu Technologie variieren. - Raw Gate Count
Der Raw Gate Count bezeichnet die maximale Anzahl an Gates, die auf dem Chip ohne die notwendige Verdrahtung untergebracht werden könnte. Dieser entspricht in etwa der Anzahl aller auf dem Chip vorhandener Grids (Grid_x X Grids_y) dividiert durch das Verhältnis Grid zu Gate (s.o.) der jeweils benutzten Technologie. - Prozeß-Utilization
Das Verhältnis von der Anzahl der untergebrachten Gates zum Raw Gate Count eines Chips wird als Utilization (Nutzung) bezeichnet und ist immer deutlich unterhalb von 100%. Abhängig von verschiedenen Faktoren bewegt sich die Utilization im Bereich von etwa 50% bis 80%. Ausnahmen bestätigen auch hier die Regel (s.u.). Die Utilization wird vor allem durch den Aufwand für die Verdrahtung der Schaltung reduziert. Kann die mittlere Länge der elektrischen Verbindungen kurz gehalten werden, benötigen diese eine geringere Fläche, womit letzten Endes mehr Platz für die eigentliche Schaltung zu Verfügung steht - die Utilization steigt daher.
Die Utilization wiederum ist von vielen teilweise nicht meßbaren Faktoren abhängig:
- Innere Designstruktur
Ist die innere Struktur einer Schaltung unregelmäßig und müssen für die Verdrahtung weite Strecken überbrückt werden, drückt der hohe Verdrahtungsaufwand die Utilization. Hat das Design eine regelmäßige Struktur, in der die Elemente quasi nacheinander angeordnet werden können, ist die mittlere Verdrahtungslänge relativ kurz und die Utilization höher. - Makrokonfiguration (z.B. RAMs)
Makros sind innerhalb der Schaltung plaziert und können für bestimmte Verbindungen ein Hindernis darstellen. Verbindungen, die um Makros herum oder an ihnen vorbei geführt werden, sind daher relativ lang und können die Utilization erheblich reduzieren. Zwischenräume zwischen zwei oder mehreren Makros können eine darin plazierte (Teil-)Schaltung eine extrem ungünstige Geometrie darstellen mit entsprechend negativen Auswirkungen auf die (lokale) Utilization der (Teil-)Schaltung. - Design Flow
Auch die Art und Weise wie ein Design implementiert wird, hat einen nicht zu unterschätzenden Einfluß auf die Utilization. Gegenüber einem flachen Layout (Flat Layout), in dem die gesamte Chipfläche homogen genutzt werden kann, entsteht in einem hierarchischen Layout (Hierarchical Layout oder Block Based Layout) zwischen den einzelnen Blöcken ein Freiraum, der ausschließlich für die Verbindungen der Blöcke untereinander genutzt wird. Diese Freiräume werden - außer durch Buffering langer Leitungen - nicht von der funktionalen Logik verwendet und reduzieren daher die Utilization der Gesamtschaltung auf dem Chip. Wie stark sich diese Reduktion auf die Gesamt-Utilization auswirkt, ist von
- der Anzahl der Blöcke
- der internen Utilization der Blöcke
- der Geometrie und die Anordnung der Blöcke in der Core Area mit einer
daraus resultierenden nicht nutzbare Restflächen zwischen den Blöcken
- dem Flächenbedarf der Signalführungen zwischen den Blöcken und zu den IOs
abhängig. Um bei einem hierarchischen Layout die Reduktion der Utilization im Rahmen zu halten, ist vor den eigentlichen Layout-Schritten eine detaillierte Planung des Top-Level erforderlich, in der die aufgeführten Faktoren "geschickt" berücksichtigt werden. u.U. wird in diesem Schritt auch Einfluß auf die Anordnung der IOs genommen. - Pad limited und Area limited Design
Benötigt ein Design extrem viele Pins bzw. Pads, kann die in der Core Area eingeschlossene Fläche weitaus größer sein als für die Schaltung bei einer typischen Utilization benötigen würde. Oder anders herum ausgedrückt. Bezogen auf den typischen Flächenbedarf der Schaltung fehlen einige bis viele IO-Pads. In diesem Fall bleibt ein mehr oder weniger großer Teil der Core Area ungenutzt und die Utilization des Designs wird entsprechend schlecht.
Der andere Fall Area limited Design erzwingt zwar keine schlechtere Utilization innerhalb der Core Area, jedoch sind außen um die Core Area herum mehr IO-Slots angeordnet als nötig, was letztendlich auch die Chipfläche unnötig vergrößert. Typischerweise werden hier nicht benutzte Gehäuse-Pins als zusätzliche Versorgungsspannungs-Pins genutzt.
Weiter zur Prozessierung eines Wafers
![]()
[Home] [ASICs] [Selbstmanagement] [Inselmeer] [Spiele]
[Ich über mich] [Links] [SiteMap] [Disclaimer]